




C#. Статьи о C#.
Статьи по теме языка программирования C#. Перейти »

Всякая всячина...
Статьи и заметки, которые могу быть интересны не зависимо от языка программирования, на котором они реализованы. Перейти »
Генерация случайных чисел в C#

Доброго времени суток! Эта статья носит практический характер и в ней я расскажу о том, как использовать генератор случайных чисел в C# и для чего это Вам может пригодиться. Хотя, если на чистоту, то речь пойдет о генераторе псевдослучайных чисел…
Где нам могут понадобиться случайные числа, да на самом деле можно привести в пример много случаев, например, криптография, или механизмы разрешения различных коллизий. Поверьте, рано или поздно Вам с такой необходимостью придется столкнуться, если уже не пришлось, раз читаете эту статью. К счастью, в C# генератор случайных чисел разработан до нас, и единственное что нам нужно будет, большинстве случаев, это просто правильно им пользоваться. И так, для генерации случайных чисел в программах, написанных на C#, предназначен класс «Random».
Освобождение ресурсов в C# (Часть 2. IDisposable)
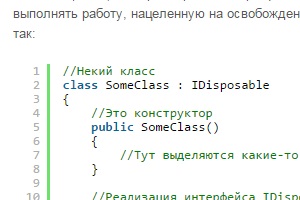
Доброго времени суток! В этой статье я продолжу рассказывать об освобождении неуправляемых ресурсов внутри объектов, в программах, написанных на C#. В предыдущей статье, я рассказывал о том, как можно выполнить эту задачу используя финализаторы, а так же, перечислил негативные стороны применения данного подхода. В этой статье, я расскажу о ещё одной возможности для освобождения ресурсов — о реализации интерфейса IDisposable.
И так, если в объектах создаваемого Вами класса используются неуправляемые ресурсы и Вы хотите разработать механизм для их освобождения, логично реализовать интерфейс IDisposable. Который содержит всего лишь один метод, как не странно, это метод Dispose (без параметров и возвращаемого значения).
Освобождение ресурсов в C# (Часть 1. Финализаторы)
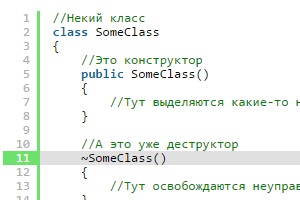
Доброго времени суток! В этой, и ряде следующих статей, я хочу поговорить об освобождении неуправляемых ресурсов, используемых в объектах классов, написанных на C#. О чем вообще пойдет речь, ведь в C# объекты удаляются сами (точнее, так называемым сборщиком мусора), т.е. программисту не нужно освобождать память из-под каждого созданного оператором new объекта, как это было в C++. Да, это так, но C# программистам всё ещё приходится работать с так называемыми, неуправляемыми ресурсами, например, файлами, или подключениями к базам данных.
Представьте пример, когда мы пишем некий «класс-обертку» над механизмом работы с файлами. Объекты такого класса будут открывать файлы (скорее всего в своих конструкторах), писать/читать информацию в них, ну и в конце концов должны «закрывать» эти файлы. В C++ такие задачи решались без особых трудностей, там были деструкторы.
Анонимные методы и лямбда-выражения в C#

Анонимные методы и лямбда-выражения
Доброго времени суток! В этой статье я расскажу об использовании анонимных методов и лямбда-выражений в связке с делегатами. Если Вы не читали две предыдущий статьи и совсем не знакомы с понятием делегата в C#, то рекомендую их (знакомство с делегатами (Часть 1 и Часть 2)) к прочтению. Для остальных, приведу пример объявления вот такого вот типа делегатов:
//Пример делегата delegate double DoubleOperation(double anAgr);
Знакомство с делегатами в C# (Часть 2)

Делегаты в C# (практика)
Доброго времени суток! В этой статье, я покажу как на практике можно использовать делегаты, и как с их помощью добиваться, в некотором смысле, универсальности (или абстракции) поведения для объектов своих классов. Эта статья является продолжением предыдущей, так что рекомендую её почитать, если Вы совсем не знакомы с делегатами в C#. И так, давайте вспомним что такое делегат… По сути, это объект, который хранит ссылку на некий метод, и может этот метод вызвать при необходимости. Точнее мы можем вызвать метод через этот объект. И особенность использования делегатов в том, что при объявлении ссылки на объект-делегат мы можем и не знать, на какой конкретно метод, будет ссылаться этот объект. Мы только знаем, что целевой метод должен иметь определенного вида список параметров и тип возвращаемого значения. А вот уже эту особенность можно использовать на своё благо! А как это сделать, я сейчас покажу на примере.
Знакомство с делегатами в C# (Часть 1)

Делегаты в C# (теория)
Доброго времени суток! В этой статье я хочу рассказать о том, что такое делегаты в C#, как их создавать и как ими пользоваться. Делегат — это сущность в программе, которая хранит ссылку на какой-либо метод, и при необходимости, может этот метод вызвать. Сразу же может возникнуть вопрос, а зачем вызывать метод через какого-то посредника, если можно вызвать его напрямую? Дело в том, что на этапе сборки программы, программист может не знать какой метод нужно будет вызвать в определенный момент выполнения программы. А использование делегатов, как раз позволяет написать, в какой-то степени, абстрактный код. Но об этом я расскажу в следующей статье, в которой покажу пример использования делегатов на практике. А пока просто поверьте мне на слово.
Ну давайте уже разберемся как создаются делегаты. Для создания делегата, нужно сначала определить его тип. Как и в случае классов, мы создаем некий шаблон, в соответствии с которым, буде в дальнейшем создавать конкретные экземпляры. Тип делегата определяется по следующему правилу:
C#. Кодо-ориентированные исключения
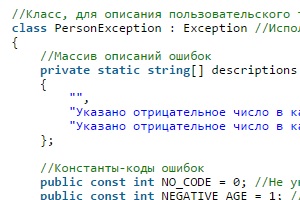
Исключения, ориетированные на коды ошибок
Доброго времени суток! В этой статье я хочу показать на практике, как в C# можно создать класс-исключение ориентированный на использование кодов ошибок. Сейчас я чуть подробнее расскажу что имею ввиду и зачем это нужно, а потом, приступим к делу.
Когда Вы пишите программу, Вам приходится думать не только о том что она должна делать, но и том, что как она должна себя вести в нестандартных ситуациях, при некорректном поведении пользователя и тому подобное. В частности, приходится сталкиваться с обработкой входных данных и информировать систему, если они некорректные. И как правило, выявляется целый ряд типов ошибок. В таком случае, программист может для каждого типа исключительных ситуаций написать отдельный класс (и такой подход оправдан в ряде случаев), но может пойти и другим путём, о котором я и расскажу в этой статье.
C#. Стратегия использования блоков catch

Использование нескольких блоков catch
В этой статье я вновь хочу коснуться темы обработки исключительных ситуаций, в программах, написанных на C#. Точнее, я хочу рассказать о нескольких нюансах, связанных с обработкой ошибок, а именно, с использованием блоков catch (блоков обработки ошибок). Как мы помним, основная идея подхода к обработке исключительных ситуаций, заключается в разделении программного кода на две части, одна представляет собой потенциально опасный блок кода (в ней могут происходить ошибки), а другая отвечает за обработку произошедших ошибок. Схематично это может выглядеть так:
Пользовательские классы-исключения в C#
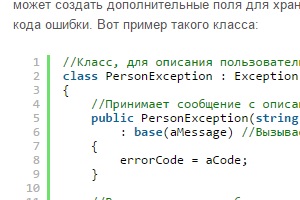
Пользовательские классы-исключения
В предыдущей статье я рассказывал о генерации исключений в программах, написанных на C#. Прочитав её, Вы узнаете для чего предназначен данный механизм и как им пользоваться. А в этой статье я хочу рассказать о том, как создавать свои классы-исключения, т.е. такие классы, объекты которых, можно использовать для генерации исключений оператором throw.
И так, как мы помним, механизм генерации исключений нужен для информирования системы, о том, что в программе произошла некая исключительная ситуация (ошибка) и дальнейшее выполнение программы, без её обработки, невозможно! А объекты-исключения, который как бы «выбрасываются в эфир» оператором throw должны содержать информацию о произошедшей ошибке. И когда Вы разрабатываете свой специфический класс, Вам нужно позаботиться о генерации исключений в нештатных ситуациях, связанных с неправильным использованием этого класса. И вот тут начинается самое интересное…
C#. Генерация исключений
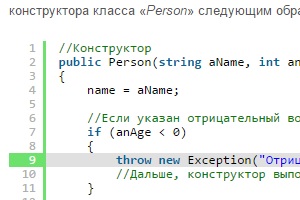
Генерация исключений
В этой статье я расскажу о генерации исключений. Под генерацией исключений, я подразумеваю создание объектов описывающих исключительные ситуации, и информирование (с их помощью) системы о том, что произошла нештатная ситуация во время выполнения программы. И так, для чего же в C# предусмотрен механизм генерации исключений? Понимаете, в практике, программисту приходится не только обрабатывать ошибки, которые могут произойти во время выполнения программы, но и информировать систему, о том, что произошла какая-то ошибка в коде, который пишет он сам. Для понимания сути проблемы, давайте рассмотрим пример одного класса:
